发展史
谷歌用来翻译,编码解码
文字数字化,位置向量化,语义关系化,预测概率化
llama-2-70b 140g文件 700亿参数(10tb数据集,6000显卡训练12天,200w美元)
实现原理:返回之前所有输入预测下一次字的概率(反复)
原理
1、tokenization 文字转数字 input->token vocab_size(常用tiktoken)总共的token
2、位置信息编码 加入位置数字1,2,3,4,5 不同位置维度也不一样 行列都不一样 使用正玄和余玄 -1~1(做位置信息面吗)偶数sin 奇数cos
矩阵相乘与几何逻辑
一个数字:标量,一行数字:向量,很多向量:矩阵 矩阵相乘:[4,3]x[3,4]=[4,4] (3和3要相等才能相乘又叫点积计算)
线性变换:矩阵和一个向量相乘 [4,3]x[3,1]=[4,1] 余弦相似度 cos = axb矩阵相乘/ab长度
ab矩阵相乘=a长度xb在a的投影长度
神经网络
layernorm以及softmax
层规划化(数字缩放)1、均值为零2、方差为一 pytorch的公式 nn.LayerNorm(bias=True) bias偏差
Softmax 数字变概率 torch.softmax()
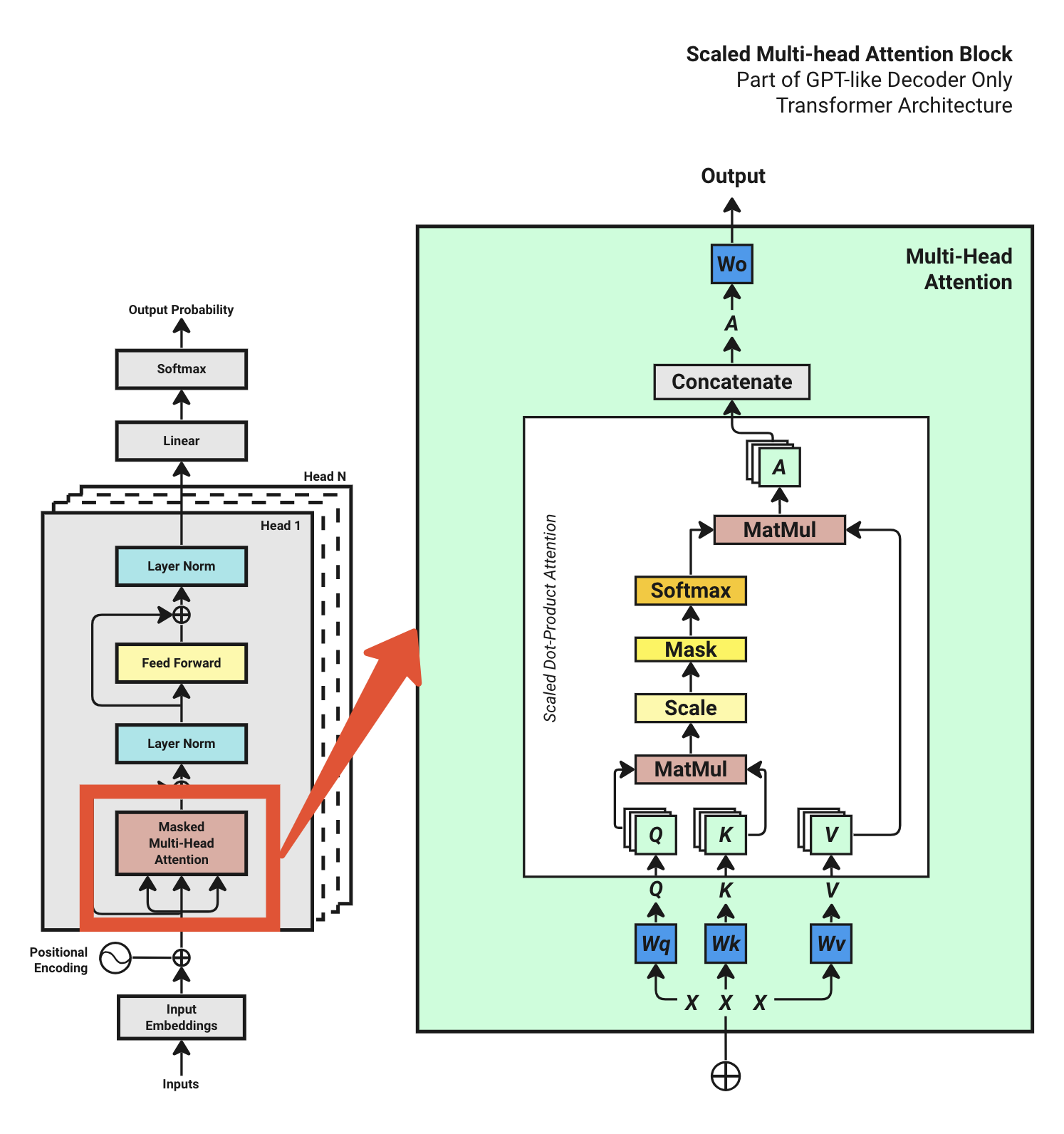
多头注意力机制QKV
x:[4,16,512]=[bath_size,ctx_length,d_model] 批次,文字长度,学习维度
qw [4,16,512]x[16,512]=[4,16,512]
切分多头
[4,16,512] -> [4,16,4,128] num_heads -> 矩阵变形 [4,4,16,128] d_model=>d_key
Q: [4,4,16,128] K: [4,4,128,16] QK=[4,4,16,16] (Q转型就是倒过来就是K)
Scale除以一个根号缩放一下,Mask遮挡,Softmax数字改百分比
A是 [4,4,16,128]
concatenate多头合并 [4,16,512] 乘Wo[512,512]=output [4,16,512]