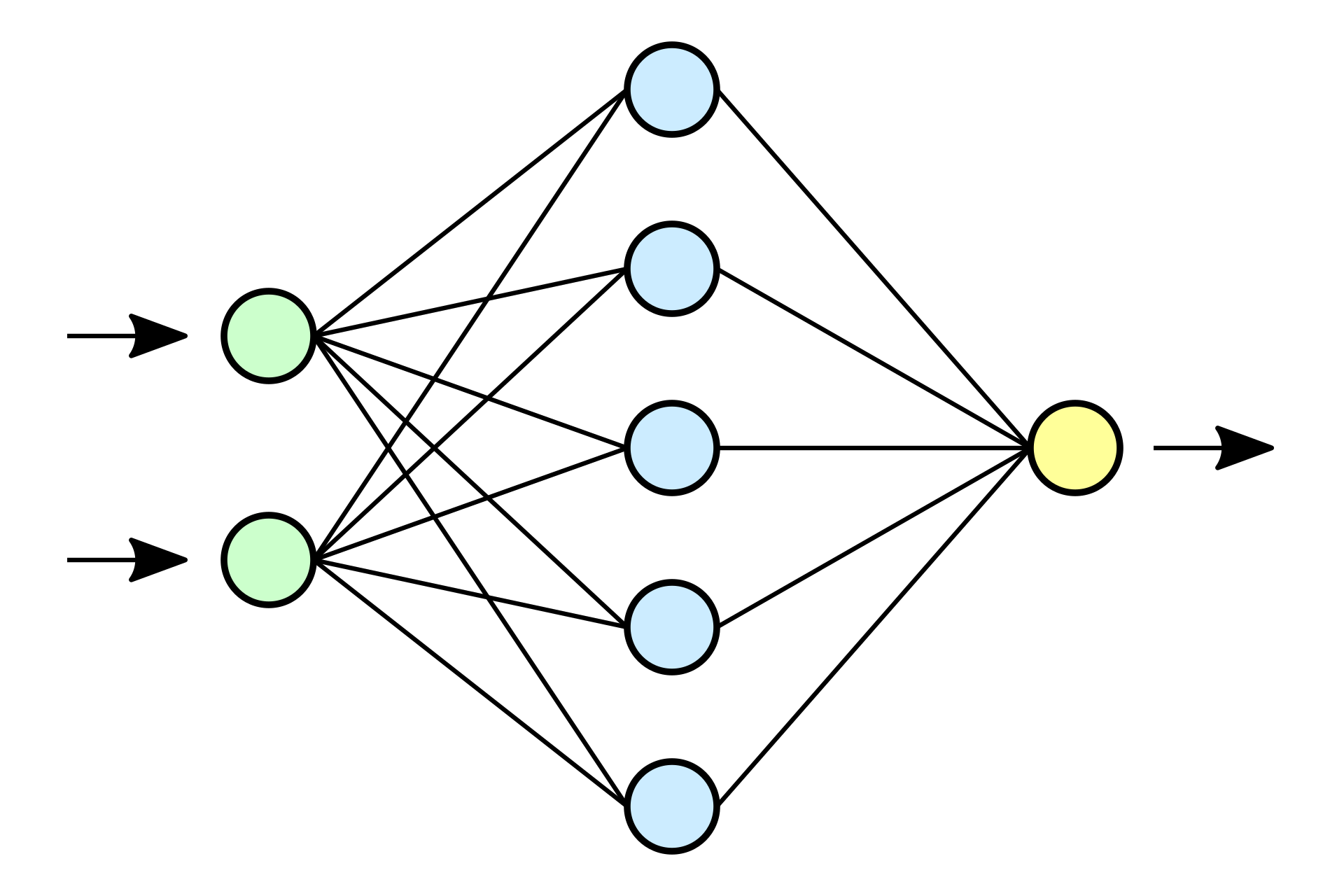
输入层 隐藏层… 输出层
a=h(wx+b)
激活函数 (非线性)sigmod 就变成了逻辑回归
隐藏层里面一般有激活函数
激活函数
sigmoid 适用于分类 0-1 但是反向传播的时候梯度容易消失
tanh -1 1 0点对称
relu 梯度不会消失 但是训练的时候可能神经元死亡
leaky relu
输出层激活函数 softmax 0-1
前向传播
均方误差损失函数
train test
链式法则
对之前w一层一层求导
反向传播
来计算w 更新梯度
输入层 隐藏层… 输出层
a=h(wx+b)
激活函数 (非线性)sigmod 就变成了逻辑回归
隐藏层里面一般有激活函数
sigmoid 适用于分类 0-1 但是反向传播的时候梯度容易消失
tanh -1 1 0点对称
relu 梯度不会消失 但是训练的时候可能神经元死亡
leaky relu
输出层激活函数 softmax 0-1
均方误差损失函数
train test
对之前w一层一层求导
来计算w 更新梯度
扫码打开当前页
之前